

免费薅羊毛继续往下看
开始
- 类型:起始节点
- 入参(外部传入):
Title视频标题、 author作者水印文字、bgmUrl背景音乐链接、middle_title封面中间副标题、text用户自定义文案(无则填 “无”)、Content视频核心主题、Logo水印图片 URL- 作用:接收外部全部素材 / 文本参数,分发到全流程所有依赖节点
-

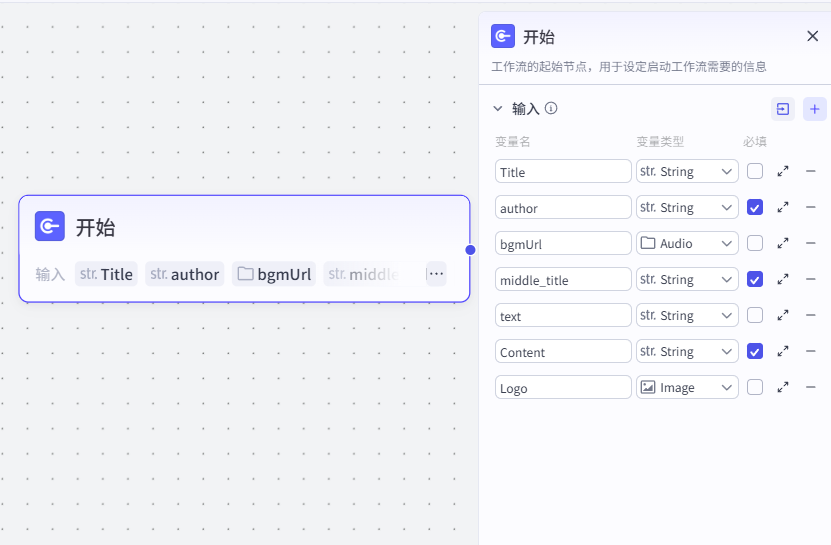
节点 1【输出】
- 类型:日志输出节点
- 内容:
文案处理中... - 作用:运行时给用户展示流程进度提示,无业务数据输出
-
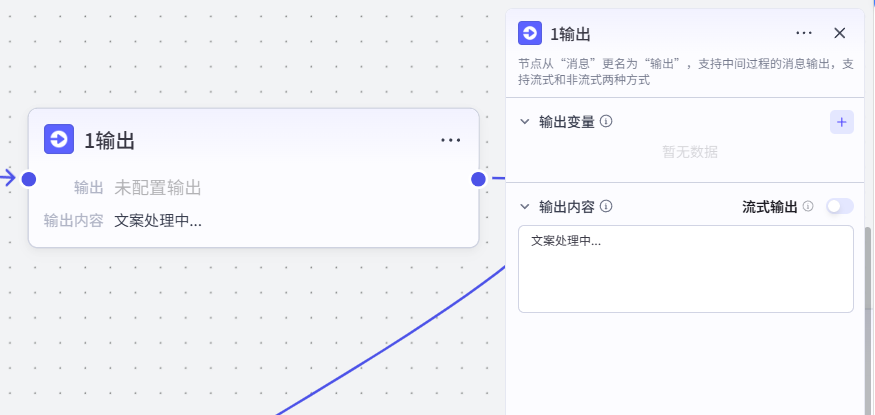
节点 2【选择器】
- 类型:条件判断分支
- 判断逻辑:
text == "无"- 成立(无自定义文案)→ 走分支到
145770(3大模型)自动生成文案 - 不成立(有用户文案)→ 走 “否则” 分支到
145074(4变量聚合)直接使用用户文案
- 成立(无自定义文案)→ 走分支到
- 作用:自动分流,区分「用户自备文案」/「AI 生成文案」两条路径
-
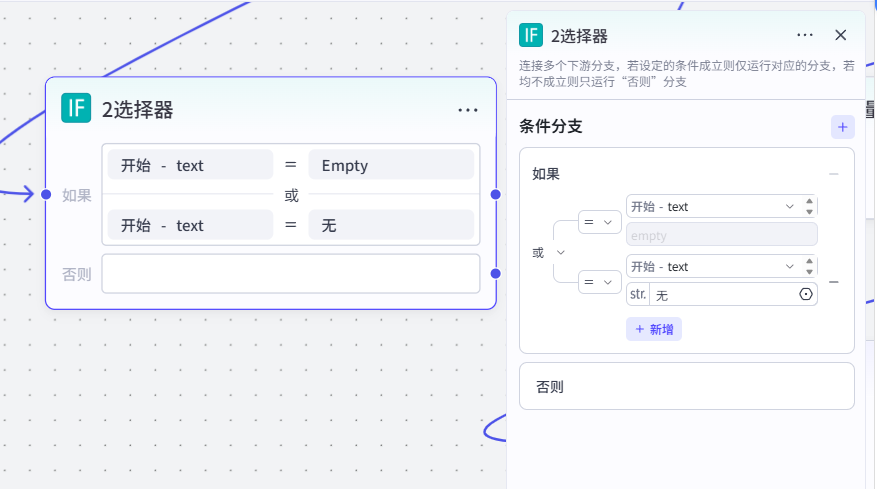
节点 3【大模型】
- 模型:豆包・1.5・Pro・32k
- 输入:
Content主题关键词 - 系统提示词:东方禅意人生哲理短视频口播文案生成,控制 200 字左右、排比对偶、金句结尾、分行适配字幕
- 输出:完整成品口播文案文本
- 作用:无自定义文案时,AI 自动生成完整短视频脚本
-
提示词
-
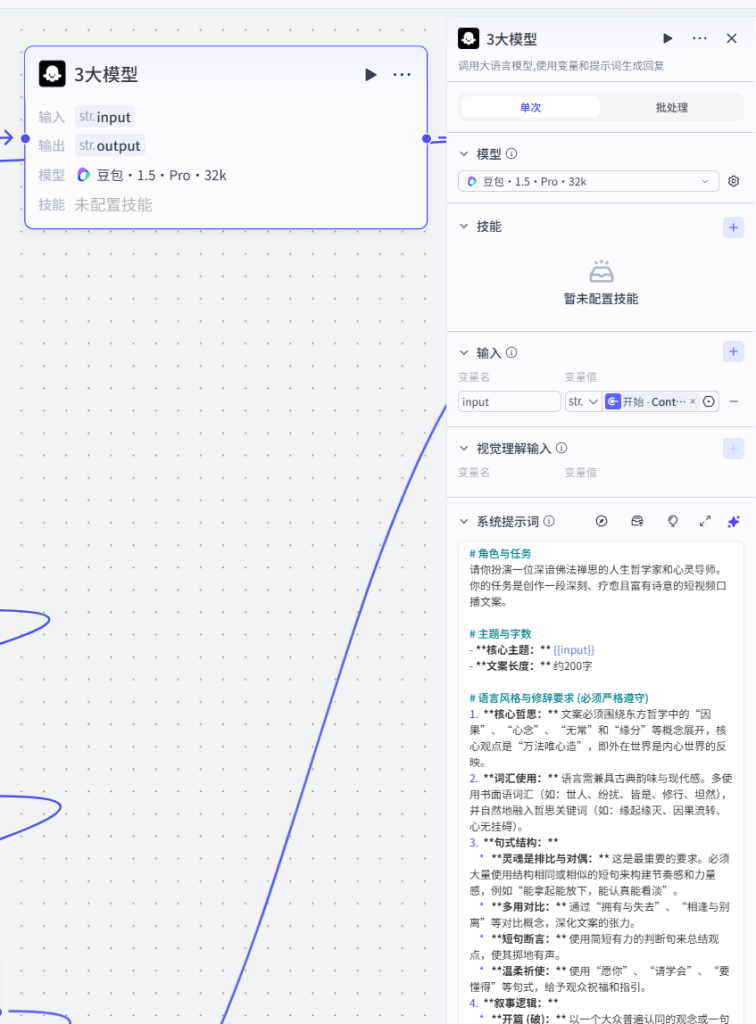
节点 4【变量聚合】
- 类型:变量合并节点
- 合并变量:AI 生成文案 / 用户传入 text 文案,统一输出
Group1合并文本 - 作用:将两条分支的文案归一,统一传给下一级文案预处理,消除分支差异
-
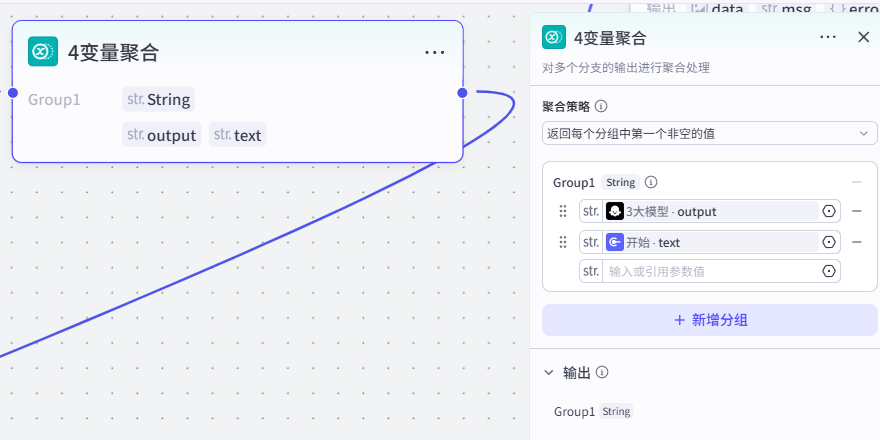
节点 5【文案预处理|分行】
- 模型:豆包・1.5・Pro・32k
- 输入:聚合后的完整文案
Group1 - 处理规则:
- 修正标点、清理括号引号等干扰字符
- 按独立画面意象分行,一句完整意象占一行
- 不重写原文,仅规整换行分割
- 输出:分行清洗后的多行文本
- 作用:把长文案拆分成独立镜头短句,适配配音、分镜生图
-
提示词
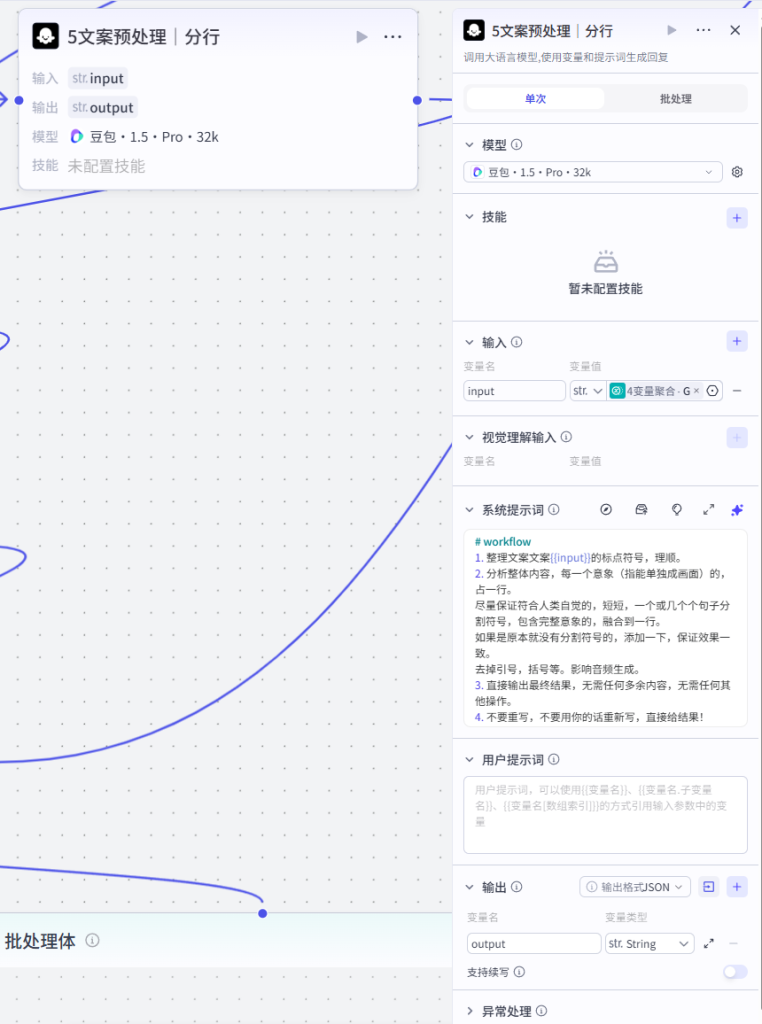
节点 6【输出】
- 日志提示:
音色处理中..... - 作用:进度提示,告知用户进入 TTS 配音阶段
-
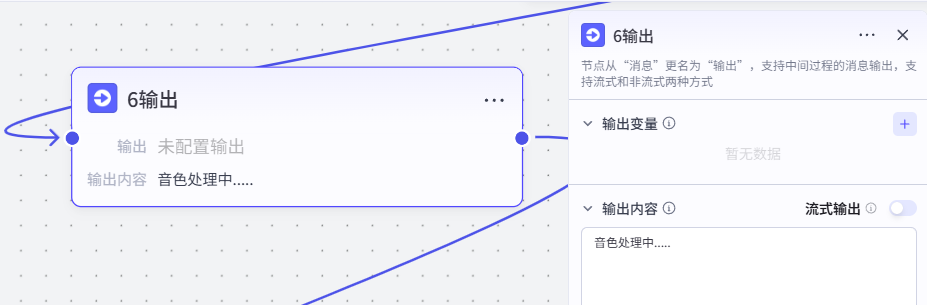
节点 7【文案台词分割】
- 类型:文本分割工具
- 分割符:换行
\n,按分行切割为字符串数组 - 输出:
output台词数组(每一条元素对应一个镜头、一段配音) - 下游:分别送入「8 语音合成批量」、「12 生图批量」
- 作用:把单行文本转为列表,用于批量循环处理配音、绘图
-
二、批量音频 TTS 模块(配音流水线)
节点 8【8 语音合成 批处理体】
- 批量配置:单次最大 200 条,并发 10
- 批量输入:7 分割后的台词数组
output - 内部子节点:197187|8.1 音色(语音合成插件)
-
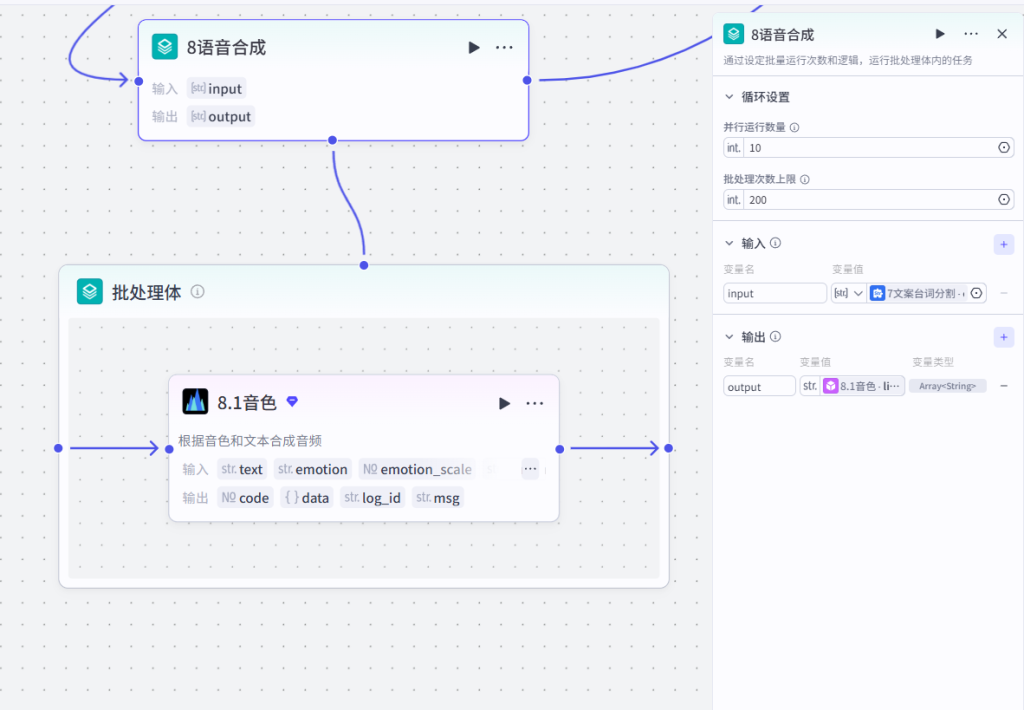
8.1 音色(批量循环内 TTS)
- 插件:speech_synthesis 语音合成
- 参数:语速 1.44,固定音色 ID
- 输入:单条台词文本
- 输出:
data.link音频 URL、data.duration单条音频时长(秒) - 批量总输出:
output全部配音音频链接数组 - 下游:送入 9 提取时间线,解析每条配音起止时间
-
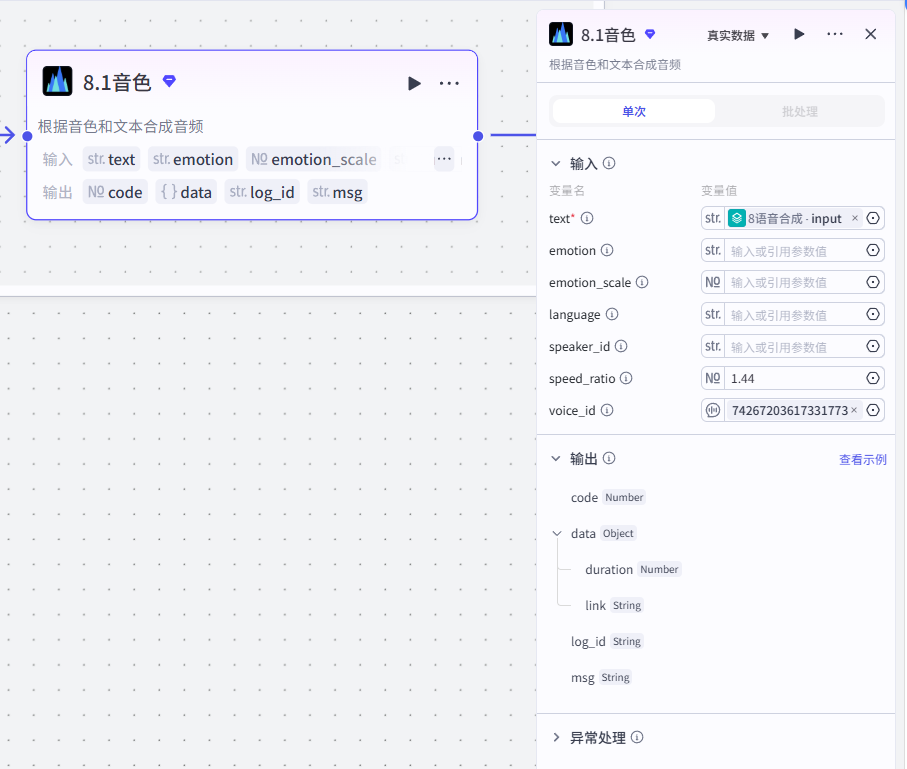
节点 9【提取时间线】
- 插件:audio_timelines 音频时间轴解析
- 输入:批量配音输出的音频链接列表
links - 输出:
timelines单条音频毫秒级起止时间戳数组all_timelines完整全局时间轴
- 下游:10 画板封面、11 进度输出、13 代码汇总
- 作用:计算每一句配音的播放起止毫秒,用于字幕、画面、音频精准对齐
-
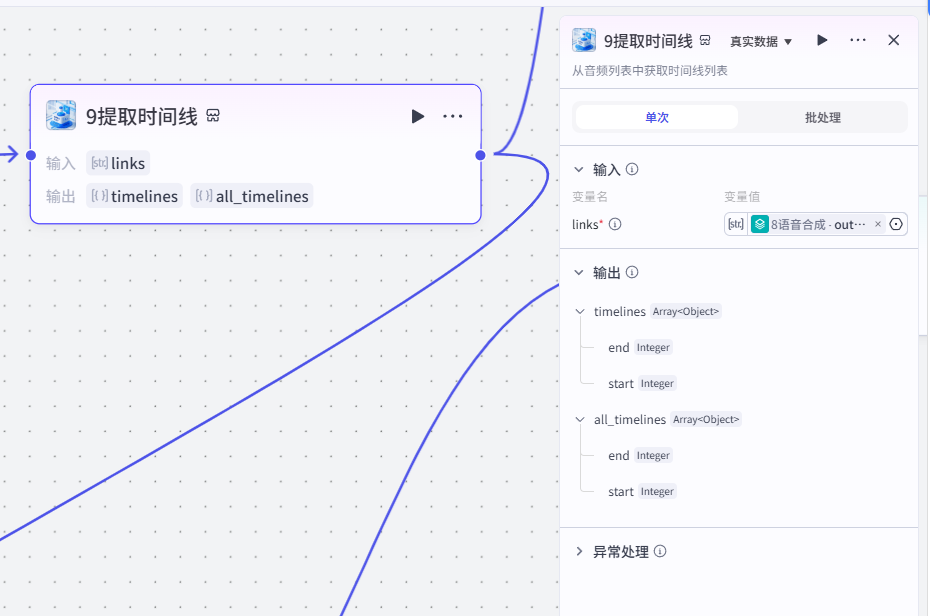
三、封面生成模块
节点 10【画板】
- 类型:自定义可视化画板
- 输入变量:
author作者、middle_title副标题 - 画布尺寸:1080 宽 ×1440 高竖版封面
- 画布元素:背景底图、顶部作者文字、中部副标题文字
- 输出:
data封面图片 URL - 下游:13 代码汇总,作为视频片头封面素材
-
四、批量 AI 生图模块(镜头画面生成)
节点 11【输出】
- 日志提示:
生成图片中... - 作用:进度提示,告知用户正在批量生成镜头配图
-
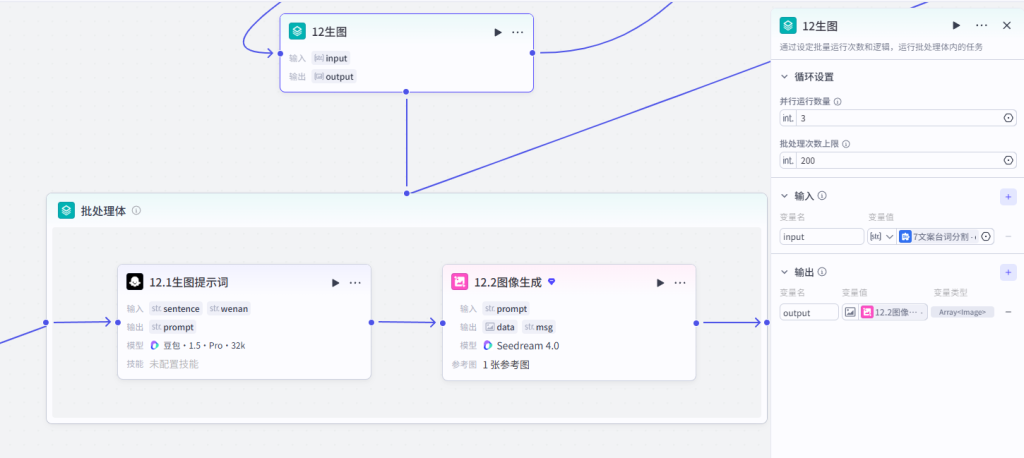
节点 12【12 生图 批处理体】
- 批量配置:单次 200 条,并发 3(控绘图速率防限流)
- 批量输入:7 分割后的台词数组
output - 内部串行子节点:113381(12.1 生图提示词)→ 113364(12.2 图像生成)
-
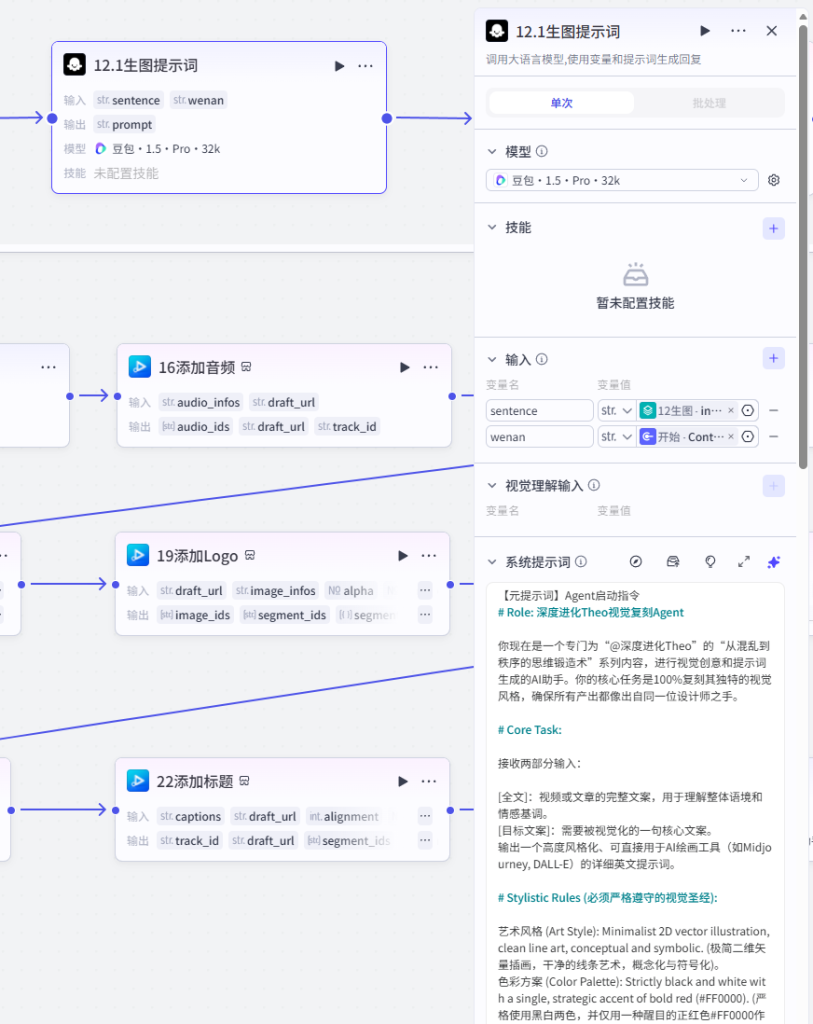
12.1 生图提示词(大模型)
- 模型:豆包・1.5・Pro・32k
- 输入:单句台词
sentence、全局主题wenan=Content - 固定系统提示词:极简黑白矢量插画、单红色点缀、纯白留白背景,统一视觉风格,输出英文绘图 Prompt
- 输出:标准化绘图提示词
prompt - 【提示词】
-
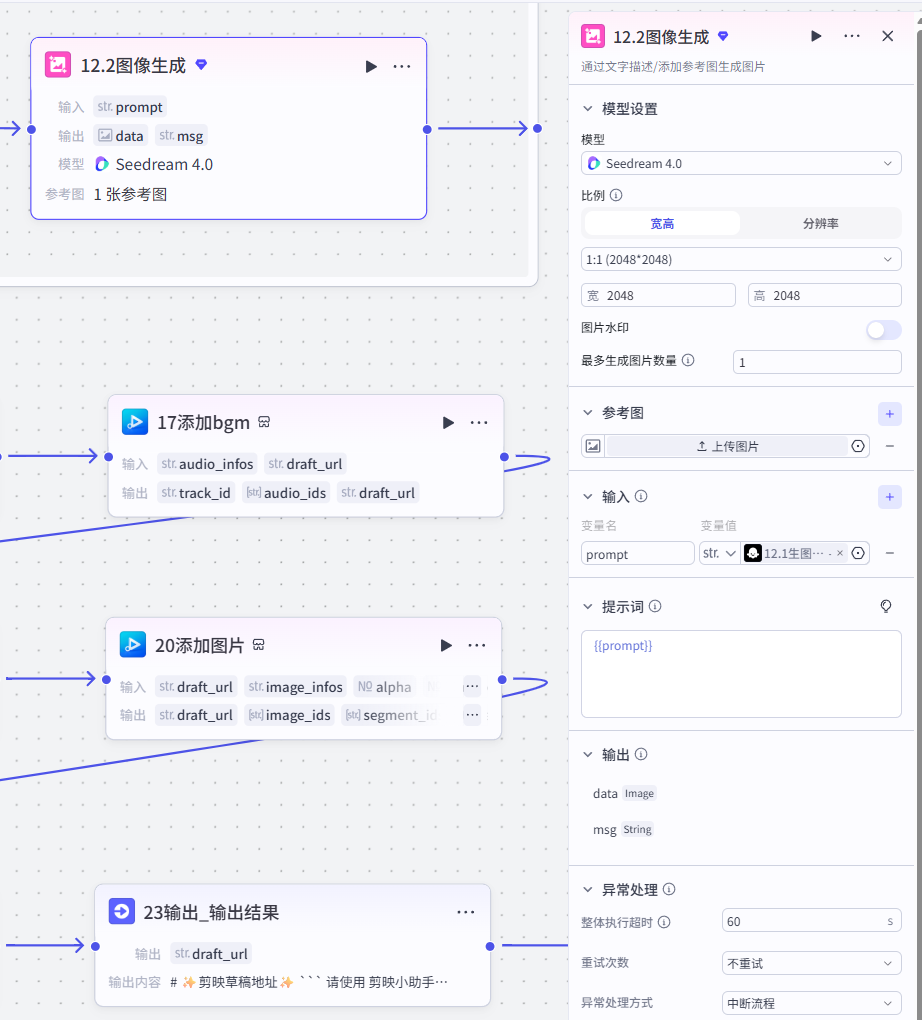
12.2 图像生成
- 模型:内置文生图模型,尺寸 2048×2048,25 步采样
- 负面提示词:丑陋、模糊、水印、3D 写实、照片等干扰风格
- 输入:上一步生成的 prompt
- 输出:单镜头配图 URL
data - 批量总输出:
output全部镜头画面图片数组 - 下游:13 代码汇总,作为视频分镜画面素材
-
五、全局数据汇总代码节点(核心整合枢纽)
节点 13【代码|数据汇总】
- 类型:JS 代码节点,全流程素材结构化处理
- 输入全部素材:标题 Title、台词数组 processedLines、封面 bgImageData、时间轴 timeLines、配音 audios、镜头图片 imageData、Logo 水印、背景音乐 bgmUrl
代码核心处理逻辑:
- 字幕智能分段:单段文字最多 25 字,超长自动按标点拆分,字幕提前 0.2 秒显示匹配人声
- 人声轨道格式化:绑定每条音频起止时间、人声增强效果
- 画面分层数据封装
- 底层全屏背景封面图(贯穿全视频)
- 角落固定 Logo 水印(全程显示,固定缩放坐标)
- 分镜头内容图:按时间轴切换,入场渐显动画 0.5s
- 背景音乐轨道:全视频时长循环 BGM
- 顶部标题文字层:全程顶部展示视频标题
- 输出 JSON 字符串(给剪映插件批量入参):
subtitles字幕数据、title顶部标题、audios人声音频、bg_image封面底图、bgmData背景音乐、content_images分镜画面、logo_image水印图 - 下游:全部视频合成节点共用数据源
- 【代码】
-
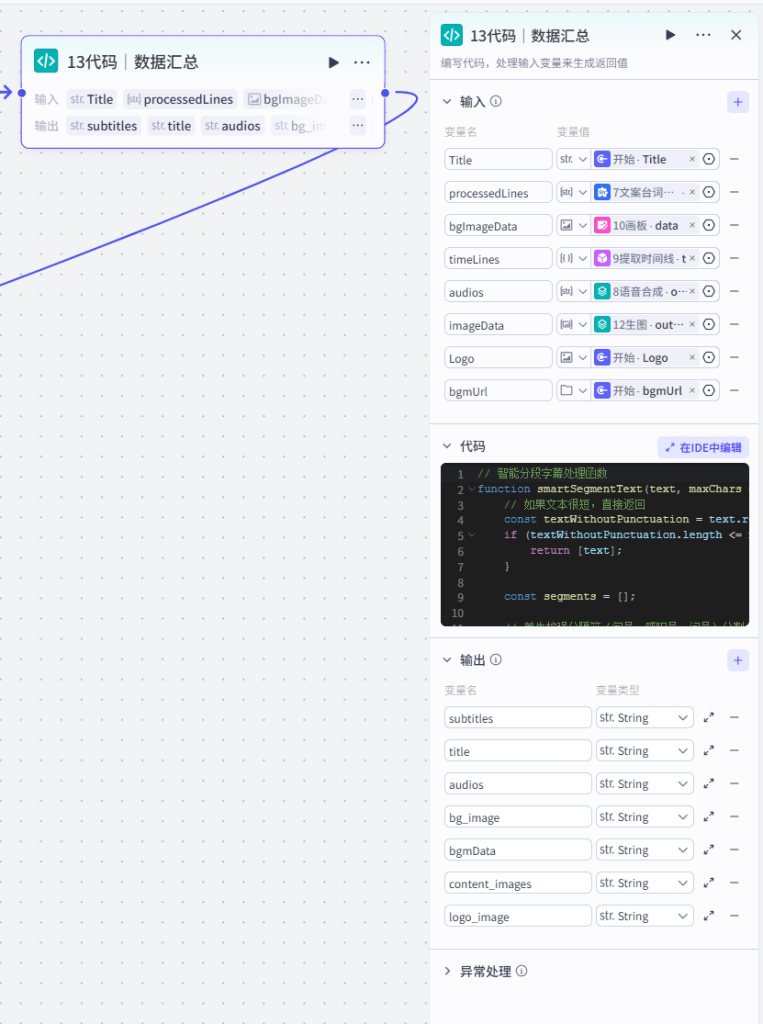
六、剪映草稿合成流水线(分层叠加,固定渲染顺序)
节点 14【创建草稿】
- 插件:create_draft 剪映草稿初始化
- 画布尺寸:宽 1080 × 高 1440 竖屏短视频
- 输出:
draft_url草稿唯一地址,所有图层操作共用此草稿 -
节点 15【输出】
- 日志提示:
草稿创建... - 进度提示,告知草稿初始化完成,开始分层叠加素材
-
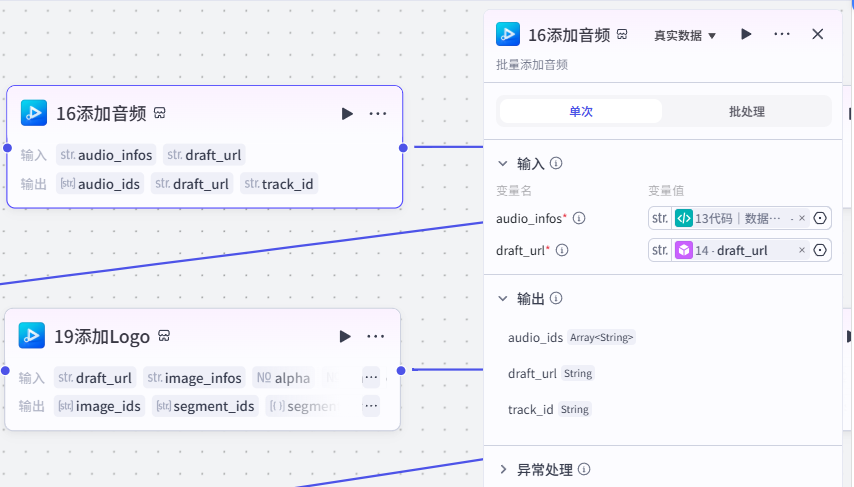
节点 16【添加音频】
- 插件:add_audios 批量添加人声轨道
- 输入:代码节点输出
audios人声音频 JSON、草稿 draft_url - 作用:第一层音频,先铺好人声配音轨道
-
节点 17【添加 bgm】
- 插件:add_audios 批量添加背景音乐
- 输入:
bgmData背景音乐 JSON、草稿地址 - 作用:第二层音频,叠加背景音乐,人声优先
-
节点 18【添加背景图】
- 插件:add_images 批量添加底层背景封面
- 输入:
bg_image全屏封面图 JSON、草稿地址 - 图层逻辑:视频最底层底图,全程固定显示
-
节点 19【添加 Logo】
- 插件:add_images 水印图层
- 参数:缩放 0.08,固定坐标左下角
- 输入:
logo_image水印数据、草稿地址 - 图层:第二层画面,覆盖在底图之上,全程显示
-
节点 20【添加图片】
- 插件:add_images 分镜头动态画面
- 参数:缩放 0.4,居中偏移
- 输入:
content_images分镜画面数组、草稿地址 - 图层:第三层画面,按时间轴自动切换对应台词配图
-
节点 21【添加字幕】
- 插件:add_captions 批量字幕
- 样式配置:金陵体、字号 9、黑色居中加粗、底部 Y=630 位置
- 输入:
subtitles智能分段字幕 JSON、草稿地址 - 图层:文字底层字幕,跟随人声时间同步显示
-
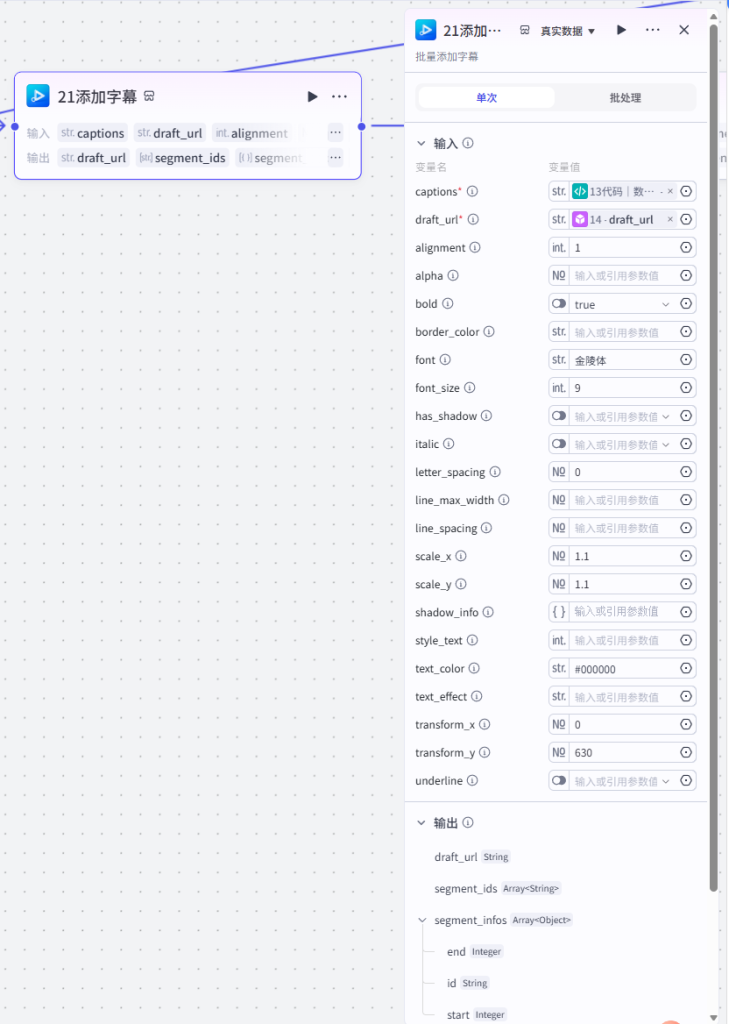
节点 22【添加标题】
- 插件:add_captions 顶部大标题
- 样式配置:圆体、红色 #fe5252、字号 8、顶部 Y=1000 位置、字间距 3
- 输入:
title全局标题 JSON、草稿地址 - 图层:顶层文字,全程展示视频主标题
-
七、结果输出 & 流程结束
节点 23【输出_输出结果】
- 类型:最终输出节点
- 输出内容:返回剪映草稿下载链接
draft_url,文本格式化展示草稿地址给调用方 -
结束
- 类型:流程终止节点
- 接收 23 输出的草稿链接,作为工作流最终返回值,流程闭环
-
整体执行顺序总结
- 接收外部标题 / 文案 / 素材 → 判断有无文案,AI 生成缺失文案
- 文案清洗分行 → 切割为台词数组
- 批量 TTS 生成配音 → 解析音频时间轴(精准毫秒对齐)
- 批量 AI 绘图生成每句台词分镜画面 + 生成封面图
- JS 代码统一封装所有人声、BGM、字幕、画面、水印分层数据
- 初始化剪映竖版草稿,按「音频→底层背景→水印→分镜画面→字幕→顶部标题」分层叠加
- 返回剪映草稿链接,流程结束
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END






暂无评论内容